大型语言模型(LLM),尤其是生成式预训练 Transformer(GPT)模型在许多复杂的语言任务上表现出了出色的性能。这一突破使人们希望在移动设备上本地运行这些 LLM,以保护用户隐私。可是,即使是小型 LLM 也太大,无法在这些设备上运行。
举例来说,小型 LLaMA 有 7B 参数,其 FP16 版本大小为 14GB,而移动设备只有 18GB 的 DRAM。因此,通过训练时间优化(如稀疏化、量化或权重聚类)来压缩 LLM 是设备上 LLM 部署的关键步骤。然而,由于模型大小和计算资源开销,LLM 的训练时间优化非常昂贵。权重聚类 SOTA 算法之一 DKM,由于需要分析所有权重和所有可能的聚类选项之间的相互作用,其训练时间可变权重聚类对计算资源的需求过高。
因此,许多现有的 LLM 压缩技术,如 GTPQ 和 AWQ,都依赖于训练后的优化。在本文中,研究者提出了内存优化技术,以实现训练时间权重聚类及其在 DKM 中的应用,也就是 eDKM。
本文使用的技术包括跨设备张量编排和权重矩阵唯一化及分片。在使用 eDKM 对 LLaMA 7B 模型进行微调并将其压缩为每个权重因子占位 3bit 时,研究者实现了解码器堆栈约 130 倍的内存占用减少,优于现有的 3bit 压缩技术。
提高 DKM 的内存效率
如图 1 所示,剪枝、量化和归一化都是较为流行的权重优化技术,这些方法将原始权重 W,优化后得到权重  ,以优化推理延迟、精度或模型大小。在这些技术中,本文研究者主要关注的是权重聚类,特别权重聚类算法 DKM 。
,以优化推理延迟、精度或模型大小。在这些技术中,本文研究者主要关注的是权重聚类,特别权重聚类算法 DKM 。
权重聚类是一种非线性权重离散化,权重矩阵被压缩成一个查找表和查找表的低精度索引列表,现代推理加速器可以处理这些索引。DKM 通过分析权重(以 W 表示)和中心点(以 C 表示)之间的相互作用来执行可微权重聚类,并在压缩比和准确性之间做出权衡。
因此,使用 DKM 进行 LLM 压缩会产生高质量的结果。然而,DKM 计算过程中产生的注意力图较大,前向 / 后向传递的内存复杂度为 O (|W||C|)(即图 1 中的矩阵),这对 LLM 压缩来说尤其困难。举例来说,一个 LLaMA 7B 模型仅计算 4 bit 权重聚类的注意力图就需要至少 224GB 的内存。

图 1:权重优化系统概览。DKM 中,系统内部创建了一个可微分权重聚类的注意力图谱。
因此,研究者需要利用 CPU 内存来处理如此大的内存需求,也就是先将信息存储至到 CPU 内存,然后在需要时再复制回 GPU。然而,这将在 GPU 和 CPU 之间产生大量的流量(会因此减慢训练速度),并需要巨大的 CPU 内存容量。这意味着减少 CPU 和 GPU 之间的事务数量并最大限度地降低每次事务的流量至关重要。为了应对这些难题,研究者在 PyTorch 中引入了两种新型内存优化技术。
- 跨设备的张量编排:跟踪跨设备复制的张量,避免冗余复制,从而减少内存占用,加快训练速度。
- 权重唯一化及分片处理:利用 16 bit 权重仅有 216 个唯一值这一事实来减少注意力图(如图 1 所示)的表示,并进一步将其分割给多个学习模型。
跨设备张量编排
PyTorch 用数据存储来表示张量,数据存储链接到实际的数据布局和元数据,元数据用于保存张量的形状、类型等。这种张量架构让 PyTorch 可以尽可能地重复使用数据存储,并有效减少内存占用。然而,当一个张量移动到另一个设备上时(如从 GPU 到 CPU),数据存储就不能重复使用,需要创建一个新的张量。
表 1 举例说明了张量在 PyTorch 设备间移动时的内存占用情况。在第 0 行分配的张量 x0 在 GPU 上消耗了 4MB。当其视图在第 1 行中改变时,由于底层数据存储可以重复使用(即 x0 和 x1 实际上是相同的),因此不需要额外的 GPU 内存。然而,当 x0 和 x1 如第 2 行和第 3 行那样移动到 CPU 时,尽管 y0 和 y1 可以在 CPU 上共享相同的数据存储,但 CPU 内存消耗却变成了 8MB,这导致 CPU 内存冗余,并增加了 GPU 到 CPU 的流量。

表 1:LLM 微调可能需要使用 CPU 内存来卸载 GPU 上的内存占用。缺乏跨设备的张量管理会导致跨设备的冗余拷贝(尤其是当计算图很复杂时),这对于 LLM 的训练时间优化尤为不利。例如,虽然 x0 和 x1 是相同的张量,只是视图不同,但当复制到 CPU 时,生成的张量 y0 和 y1 并不共享数据存储,而在 GPU 上 x0 和 x1 共享数据存储。
为了解决这种低效问题,研究者在图 2 (b) 中放置了一个编排层,其中黑色代表实际数据存储和元数据,灰色仅表示元数据。图 2 (a) 展示了表 1 中的示例,其中 x1 与 x0 共享数据布局,但 y0 和 y1 在 CPU 上拥有重复的数据存储。如图 2 (b) 所示,通过插入编排层,研究者避免了这种冗余,并减少了 GPU 传至 CPU 的流量。研究者使用 PyTorch 中的 save-tensor-hook 来实现这样的交换方案,检查相同的数据存储是否已经被复制。
然而,使用这样的方案来检查目标设备上是否存在相同的张量是很昂贵的。在图 2 (b) 的示例中,研究者并没有将 x1 复制到 CPU,而是简单地返回了 y0 的引用以及 x1 和 y0 之间的视图操作。

图 2:将跨设备张量编排应用于表 1 中的情况时,可以避免 CPU 端的重复,从而节省内存及流量。
浏览计算图会增加额外的计算周期,节省不必要的复制可以弥补此类开销。研究者发现,4 hop 内的搜索足以检测原始 DKM 实现中计算图中的所有合格的案例。
权重唯一化及分片处理
在大多数 LLM 的训练中,权重普遍使用 16 bit 存储(如 BF16 或 FP16),这意味着虽然 LLM 中有数十亿个参数,但由于位宽的原因,只有 216 个唯一系数。这就为大幅压缩权重和中心点之间的注意力图提供了机会,如图 3 所示。
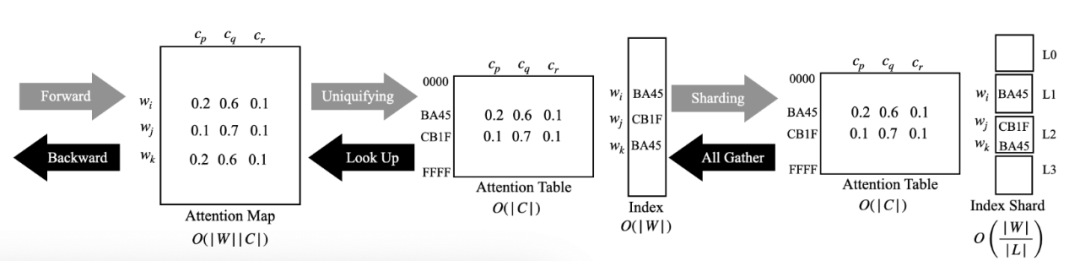
图 3:权重唯一化及分片
实验结果
LLM 准确率
本文将 eDKM 与其他基于量化的压缩方案进行了比较,包括:RTN、SmoothQuant、GPTQ 、AWQ 和 LLM-QAT 。对于 eDKM,研究者还对嵌入层进行了 8 bit 压缩。最终得出如下结论:
- eDKM 使 3 bit 压缩 LLaMA 7B 模型优于所有其他 3 bit 压缩方案。
- eDKM 在 3 bit 和 4 bit 配置的 ARC-e 基准测试中具有最佳精度。
- 在使用 4 bit 压缩模型的 PIQA 和 MMLU 基准测试中,eDKM 的性能极具竞争力。

消融实验
在消融实验中,研究者以 LLaMA 7B 解码器栈中的一个注意层为例,测量了内存占用与 3 bit 压缩的前向后向速度之间的权衡。单是跨设备张量编排就减少了 2.9 倍的内存占用,运行时开销很小,而分片和唯一化模块则分别节省了 23.5 倍和 16.4 倍。当所有技术相结合时,eDKM 可节省约 130 倍。虽然这些步骤需要额外的计算和通信开销,但由于 GPU 和 CPU 之间的流量大幅减少,因此运行时的开销微不足道。
更多详细内容,请参阅原文。

相关文章

